
Chimera GPNPUによるパフォーマンスの最適化
Chimera汎用ニューラル・プロセッシング・ユニット(GPNPU:General Purpose Neural Processing Unit)ファミリは、SoC設計者が直面する機械学習(ML)推論展開におけるさまざまな課題に対処するためにスクラッチから設計されました。従来のアーキテクチャより高いマトリクス演算処理機能をもち、シンプルかつ強力なアーキテクチャを備えています。その決定的な差別化は、単一プロセッサ上でさまざまな処理を柔軟に実行できることです。
Chimera GPNPUファミリは、マトリクス演算、ベクトル演算とスカラ(制御)コードを1つの実行パイプラインで処理可能な、統合プロセッサ・アーキテクチャを提供します。従来のSoCアーキテクチャでは、NPU、DSP、リアルタイムCPUによって各々個別に処理されるため、2つまたは3つのプロセッサ向けに、コードを手作業で分割した上で性能を調整する必要がありました。Chimera GPNPUは、単一のソフトウェア制御コアであるため、複雑な並列処理をシンプルに表現できます。
Chimera GPNPUはソフトウェアによって駆動されるため、開発者はデバイスのライフサイクルを通じて、モデルやアルゴリズムの性能を継続的に最適化できます。Chimera GPNPUは、従来のバックボーン・ネットワーク、最新のビジョン・トランスフォーマー、大規模言語モデル、そして将来開発される新しいネットワーク・モデルの実行にも最適です。
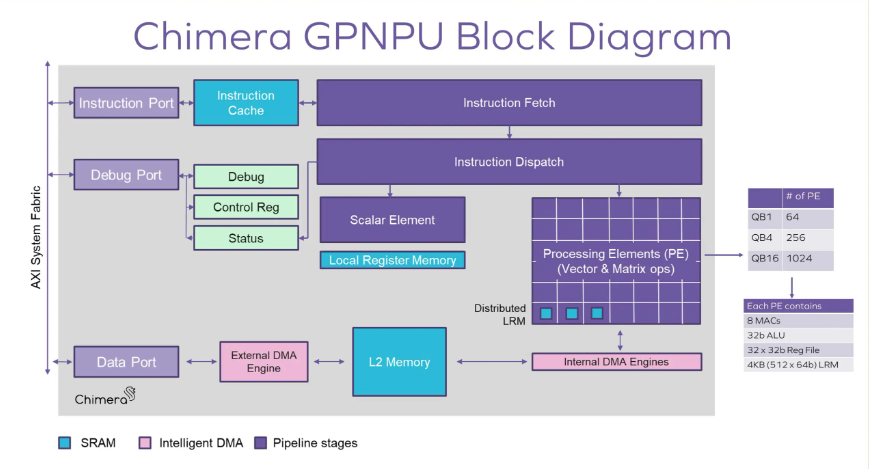 Chimera GPNPUブロック図
Chimera GPNPUブロック図
最新のSoCアーキテクチャでは、従来のC++ベースのコードと、新たに登場した日進月歩の激しい機械学習(ML)推論コードを組み合わせた複雑なアルゴリズムが採用されています。このようなグラフコードとC++コードの組み合わせは、多くのチップにおけるサブシステムで見られ、特にビジョンとイメージング・サブシステム、レーダーとライダー処理、通信ベースバンド・サブシステム、その他さまざまなデータリッチなパイプライン処理において顕著です。Chimera GPNPUアーキテクチャだけが、高いML推論性能を実現すると同時に、プロセッサ上で複雑なデータ並列化されたC++コードを実行できます。
他のML推論アーキテクチャでは2~3種類のプロセッサ向けに手作業でアルゴリズムを分割する必要がありますが、Chimeraプロセッサでは、ソフトウェア開発者の生産性を大幅に向上させると同時に、現在の処理効率と長期的な将来性を保証する柔軟性が提供されます。
Chimera GPNPUは、合成可能なRTLのソースコードで提供されるプロセッサIPコアです。ニューラル・プロセッシング・ユニット(NPU)とデジタル・シグナル・プロセッサ(DSP)の長所を融合させたChimera GPNPUは、モバイル機器、デジタル・ホーム・アプリケーション、自動車、ネットワーク・エッジ・コンピューティング・システムなど、さまざまな推論アプリケーションを対象としています。
GPNPUの特長
- システムの簡素化
クアドリックの最先端ソリューションにより、ハードウェア開発者は、MLワークロード全体と、一般的なDSPの機能や、ML推論機能と混在されることが多い信号処理を単一コアで実現できます。単一コア化することで、ハードウェアの統合が大幅に簡素化され、パフォーマンスの最適化が容易になります。十分なオフチップ帯域幅を確保するためのメモリ使用量のプロファイリングなどを活用することで、システム設計期間を大幅に短縮できます。
- プログラミングの簡素化
Chimera GPNPUアーキテクチャでは、マトリクス、ベクトル、および制御コードの全てを単一のコード・ストリームで処理できるため、ソフトウェア開発を劇的に簡素化します。一般的なトレーニング・ツールセット(Tensorflow、Pytorch、ONNX形式)からのMLグラフコードは、Quadric SDKによってコンパイルされ、C++で書かれた信号処理コードと統合することができます。
Quadric SDKは、ハードウェア開発者とソフトウェア開発者の両方の要求を満たしており、もはや複数ベンダの複数のツールセットを使いこなす必要はありません。サブシステム全体を単一のコンソール上でデバッグできます。これにより、コードの開発期間が劇的に短縮されると同時に、パフォーマンスの最適化が容易になります。この新しいプログラミング・パラダイムは、SoCのエンドユーザにもメリットをもたらします。
- 将来を見据えた柔軟性
Chimera GPNPUは、C++で書かれたものなら何でも実行できます。設計者は、SoCがテープアウトされた後でも、新しいニューラルネットワーク演算子やライブラリを実装するコードを開発し、実装することができます。これにより、将来的なエンハンスが可能となり、チップの耐用年数を劇的に延ばすことができます。
この柔軟性によって最終製品に継続的に新機能を追加し、競争力を高めることが可能になるため、SoCのエンドユーザにもメリットを与えることができます。
別々のNPU、DSP、リアルタイムCPUコアで構成される従来の異種MLサブシステムを、1つのGPNPUに置き換えることには明らかな利点があります。ベクトル、マトリクス、制御コードを単一のコード・ストリームで処理できるようにすることで、開発とデバッグのプロセスが大幅に簡素化される一方、新しいアルゴリズムを効率的に追加する能力が大幅に向上します。
MLモデルが進化し続け、推論がさらに多くのアプリケーションで普及するにつれて、この統一されたアーキテクチャから得られる利益は、チップの設計サイクルを将来にわたって保証するのに役立ちます。
Chimera GPNPUファミリ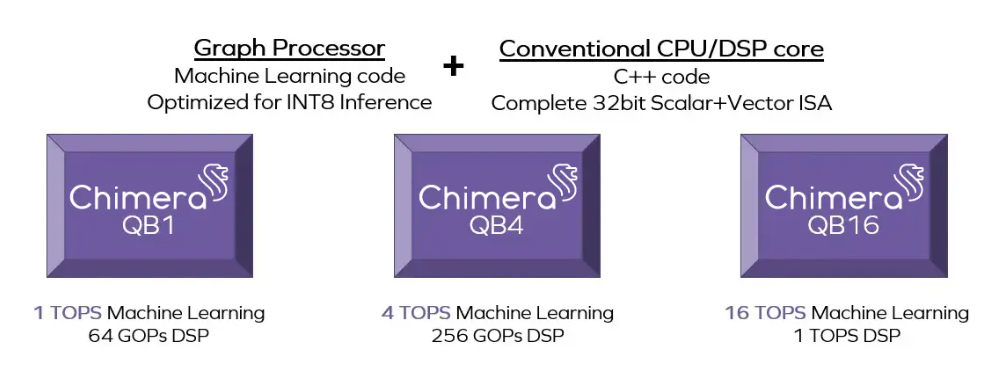
Chimera QBファミリには3つの製品があります。お客様のデザインに必要なプロセッサについてはお問合せください。複数のGPNPUを採用することもできます。
Chimera GPNPUアーキテクチャの主な特徴
– ハイブリッド・フォン・ノイマン+2D SIMDマトリクス・アーキテクチャ
– 64ビット命令、1クロックあたり1命令発行
– 7ステージ、インオーダ・パイプライン
– スカラ/ベクトル/マトリクス命令と粒度の細かい予測(Predication)モデルレスで混合
– 決定論的で非指定的な実行により、予測可能な性能レベルを実現
– システム・メモリへのAXIインターフェイス(独立したデータおよび命令アクセス)
– 命令キャッシュ(256K)
– マトリックス・アレイ内のデータ・ブロードキャスト・ネットワークと密に結合された分散ローカル・レジスタ・メモリ(LRM)により、性能を最大化するための計算とデータ移動のオーバーラップが可能
– ローカルL2データ・メモリ(マルチバンク、2MBから32MBまで設定可能)により、オフチップDDRアクセスを最小限に抑え、消費電力を低減
– INT8機械学習推論(オプションでINT16をサポート)と32ビットDSPオペレーションに最適化
– コンパイラのきめ細かなクロック・ゲーティングにより消費電力を削減
メモリの最適化=消費電力の最小化
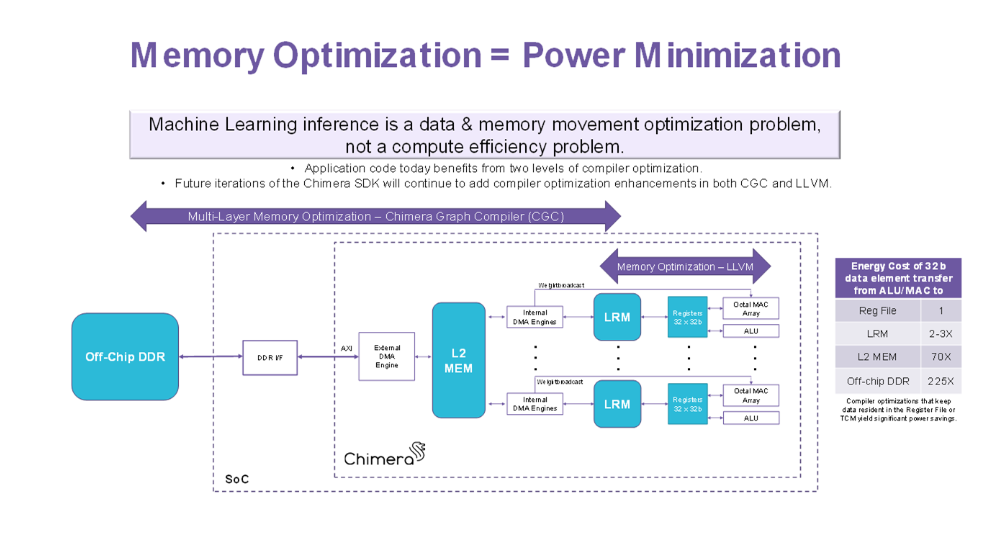
NPU、DSP、リアルタイムCPUのすべての処理を1つのGPNPUに統合した結果、大幅な省電力化を実現
機械学習推論ソリューションは、多くの場合、メモリシステムの帯域幅によって性能と消費電力が制限されます。最先端のMLモデルの多くは数十万から数百万のパラメータを持つため、MLモデル全体を先進のSoCのオンチップ・メモリに収めることは一般的に不可能です。したがって、利用可能なオンチップ・データ・ストレージの重みと活性度の両方をスマートに管理することが、高い効率を達成するための前提条件となります。SoC設計をさらに複雑にしているのは、MLモデル(演算子の種類とモデルのトポロジーの両方)の進化が、最新のSoCのライフサイクルをはるかに上回っていることです。システム・アーキテクトは、今後数年間で未知の複雑さを持つモデルを実行するために、今日IPを選択しなければなりません。
今日のシステムで使用されている第一世代のディープラーニング・アクセラレータの多くは、畳み込みやプーリングなど、いくつかの性能集約的なビルディングブロックML演算子をオフロードするハードウェアで構築された有限状態マシン(FSM)で構成されています。これらのFSMを用いたソリューションでは、SoC上で実行される最終的なネットワークが、シリコン上に予め構築された演算子パラメータの限られた範囲内に収まる場合にのみ、高い効率を実現できます。このハードウェアで構築された動作は、FSMアクセラレータでサポートされるメモリ管理戦略にも影響をおよぼします。FSMソリューションでは、ネットワー負荷の変化に応じてメモリ管理戦略を将来的に微調整することはできません。Chimera GPNPUファミリは、完全にプログラマブルでコンパイラによって生成されるプログラムによって制御されるため、この制限を解決できます。
Chimera GPNPUを搭載したSoCには、4段階のデータ・ストレージがあります。オフチップDDRは、最大規模のMLモデルにも対応する広大なストレージを実装できます。しかし、DDRへのアクセスは、消費電力と処理サイクル数の両面で不利になります。そこでChimera GPNPUは、コンパイラによって生成されるプログラムによって管理される大規模なプライベート・バッファSRAM(L2メモリ)をチップ上に搭載しています。L2のサイズは、チップ設計時に2MBから32MBの範囲で設定可能です。L2メモリは、ディープ・ニューラル・ネットワークのモデルの重みと活性化、DSPアルゴリズムの各種データと係数など、アルゴリズムの実行を高速化する上で有益なデータを保持します。L2使用量の判断はソフトウェアとコンパイラ主導で行われるため、変化するML推論の負荷に長期的に柔軟に対応できます。
豊富なDSPとマトリクス命令セット
Chimeraの命令セットは、制御、DSP、Tensorグラフ処理をカバーする豊富な演算セットを実装しています。ベースとなるプロセッシング・エレメント(PE)は、8ビット整数のディープラーニング演算用に最適化されており、16ビットMACハードウェア・オプションも設定できます。MLに特化した積和演算ハードウェアに加え、各ALUに数学関数のフルセットが用意されており、あらゆる形式の複雑なDSP演算をサポートします:
– 32ビット整数MUL/ADD/SUB/Compare
– 32ビット整数DIV(反復実行)
– 32ビットCordic関数ユニット(サイン、コサイン、Rect.からPolar/PolarからRect.、ArcX関数)
– 対数関数とExp関数
Quadric SDKには、これらの特殊関数命令を利用した一連の数式関数ライブラリが付属しており、Cordic関数、線形代数関数、フィルタリング関数、画像処理関数など、一般的な信号処理ルーチンを網羅しています。